
ScrapyをAWS Lambdaで実行するまで ①関数作成とデプロイ
AWS LambdaでScrapyを実行する
![]()
Scrapyで作成したクローラーをAWS Lambda上で実行できるようにするまでに行った手順をメモする。
AWS EC2インスタンス上からLambdaによるサーバーレス環境へのプロジェクト引越し備忘録。
環境: Scrapy 2.4.1, Python 3.9
ScrapyプロジェクトをLambdaへデプロイする
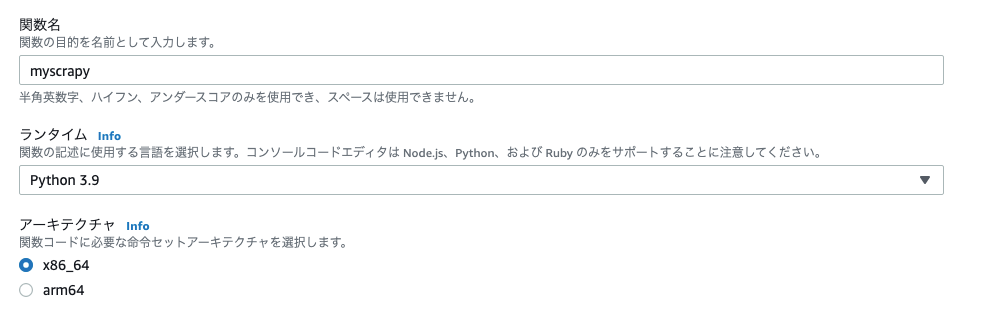
AWS LambdaマネジメントコンソールからPythonランタイムの関数を作成する。
(関数名はデプロイするプロジェクトに合わせている)
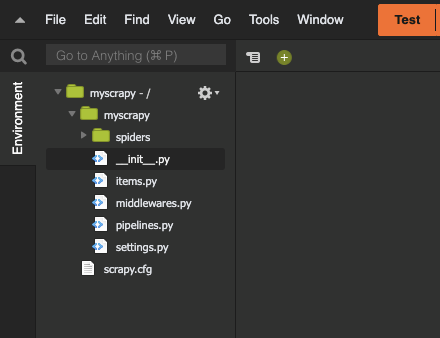
開発環境でデプロイパッケージを作成。
Scrapyプロジェクトのディレクトリ構成は下記のようになっており、プロジェクト内にもうひとつプロジェクトと同じ名前のディレクトリが存在する。
myscrapy
├── myscrapy
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
└── scrapy.cfgLambdaデプロイパッケージはプロジェクトの中身をzipファイル直下に含める必要があるので下記のようにまとめる。
cd myscrapy/
zip -r myscrapy.zip .実装の都合上、プロジェクト内でScrapy本体以外にもかなり多くのPythonライブラリやモジュールをインストールしたため、プロジェクト本体とライブラリは分けてデプロイした。
ライブラリ群はLambdaレイヤーの機能を使ってプロジェクト本体のzipとは別でデプロイし、関数に関連付ける。
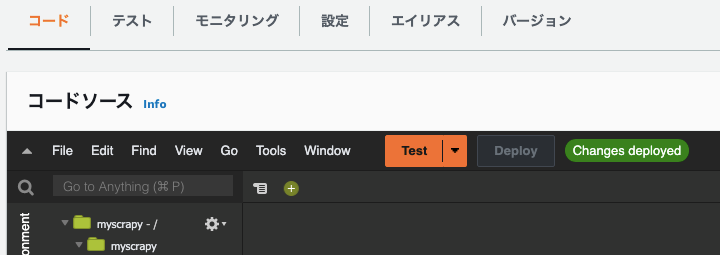
Lambda関数へデプロイ後の構成が下記のようになればOK
Lambdaハンドラーの設定
デフォルトのランタイム設定で※lambda_function.pyがハンドラー(処理の起点)となっているので、その中からScrapyの実行ファイルを呼び出す。
(Scrapyの外部実行方法については割愛する)
※ デプロイパッケージ展開時にデフォルトのlambda_function.pyを削除している場合は再度作成すれば良い。
(例)実行ファイルcrawl.pyを読み込み、Scrapy呼び出しのmain関数を実行する。
lambda_function.py
from crawl import main
def lambda_handler(event, context):
main()lambda_function.pyを作成するのが手間な場合は、実行ファイルが直接ハンドラーになるようにデフォルトのランタイム設定を変更しても良い。
before

after

プログラムの保存ができたらdeployを完了させ、Testで実行する。
Follow me!


“ScrapyをAWS Lambdaで実行するまで ①関数作成とデプロイ” に対して2件のコメントがあります。
コメントは受け付けていません。